Naive Bayes: Definisi, Tipe, Fungsi, Cara, & Plus-Minusnya

Siti Khadijah Azzukhruf Firdausi
•
03 Juni 2024
•
73218

Mau mengklasifikasikan data dalam jumlah besar dengan mudah? Algoritma Naive Bayes adalah jawabannya! Ini merupakan salah satu metode machine learning yang sering kali digunakan untuk mengklasifikasikan data.
Metode ini terkenal dengan kemudahan dan efisiensinya dalam berbagai macam aplikasi. Mau tahu lebih banyak soal Naive Bayes dan cara mengoptimalkannya untuk hasil yang lebih akurat?
Pastikan untuk baca artikel ini sampai habis, ya!
Apa yang Dimaksud dengan Naive Bayes?
Secara umum, Naive Bayes adalah salah satu jenis algoritma machine learning yang digunakan untuk mengklasifikasikan data. Algoritma ini didasarkan pada Teorema Bayes.
Mengutip dari GeeksforGeeks, Naive Bayes mengasumsikan bahwa setiap fitur atau karakteristik dalam dataset tidak saling bergantung. Artinya, keberadaan atau nilai satu fitur tidak memengaruhi fitur lainnya.
Contohnya adalah ketika menganalisis teks. Setiap kata dalam teks tersebut dianggap independen dari kata lainnya.
Selain itu, artikel tersebut menyatakan bahwa pemahaman Teorema Bayes digunakan untuk mengitung probalitas suatu data termasuk dalam kategori tertentu berdasarkan fitur yang ada.
Hal ini memungkinkan penggunanya memperbarui probabilitas berdasarkan informasi baru. Cara kerjanya adalah algoritma ini menghitung probabilitas setiap kategori untuk data yang diberikan.
Lalu, algoritmanya akan memiliih kategori dengan probabilitas tertinggi sebagai hasil klasifikasinya. Proses ini cepat dan efisien, bahkan untuk data dengan dimensi tinggi, seperti teks.
Baca Juga: 9 Langkah Optimasi Algoritma Machine Learning

Tipe Algoritma Naive Bayes
Ada beberapa jenis algoritma Naive Bayes yang berbeda berdasarkan distribusi nilai fitur yang digunakan. Berikut penjelasan singkat tentang tiga tipe Naive Bayes yang paling populer:
Gaussian Naive Bayes (GaussianNB):
Algoritma ini digunakan ketika fitur-fitur data memiliki distribusi Gaussian (normal) dan nilai kontinu. Mengutip dari IBM, model ini dibuat dengan menemukan mean (rata-rata) dan standard deviation (simpangan baku) untuk setiap kelas.
Dilansir dari geeksforgeeks, ketika data diplot dengan algoritma ini, data akan terlihat seperti kurva lonceng yang simetris terhadap mean nilai fitur.
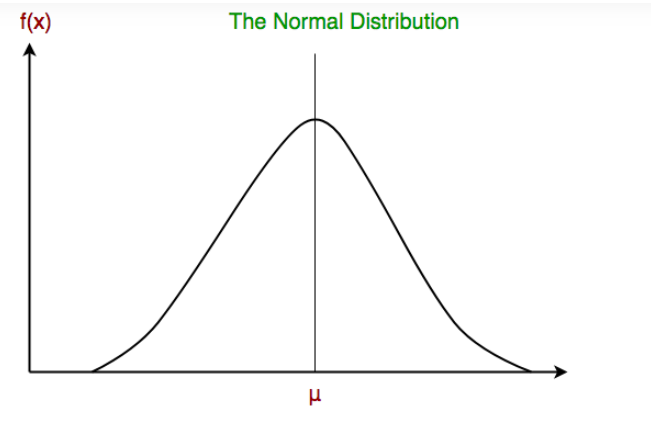
Sumber: geeksforgeeks
Contoh penggunaannya bisa berupa pengklasifikasian data dengan variabel kontinu seperti tinggi badan, berat badan, atau nilai ujian.
Selain itu, kamu juga bisa menggunakan algoritma ini untuk memprediksi penyakit pasien berdasarkan hasil tes kesehatan berkelanjutan.
Multinomial Naive Bayes (MultinomialNB)
Algoritma ini sangat berguna untuk data diskrit. Dilansir dari ibm, beberapa contoh data diskrit yang pas untuk algoritma ini adalah frekuensi kemunculan suatu kejadian. Biasanya, ini digunakan dalam pemrosesan bahasa alami (NLP).
Mengutip dari KD nuggets, ini bekerja dengan engasumsikan bahwa fitur-fitur berasal dari distribusi multinomial. Misalnya, dalam klasifikasi dokumen, fitur yang digunakan adalah frekuensi kata dalam dokumen.
Contoh penggunaannya adalah mengklasifikasikan artikel berita ke dalam kategori seperti olahraga, politik, atau hiburan berdasarkan frekuensi kata.
Bernoulli Naive Bayes (BernoulliNB)
Ini digunakan untuk variabel Boolean. Dilansir dari ibm, Boolean adalah variabel dengan dua nilai seperti True/False atau 1/0.
Dalam model ini, fitur-fitur adalah variabel biner yang menggambarkan apakah suatu kata muncul dalam dokumen atau tidak, bukan frekuensi kemunculannya.
Penerapannya bisa dalam proses klasifikasi dokumen di mana fitur yang digunakan adalah keberadaan atau ketidakberadaan kata-kata tertentu dalam dokumen.
Contoh penggunaannya adalah klasifikasi email sebagai spam atau tidak spam berdasarkan frekuensi kata, analisis sentimen, dan klasifikasi teks.
Apa Saja Fungsi Naive Bayes?
Naive Bayes memiliki berbagai fungsi yang sangat berguna dalam dunia machine learning dan analitik data. Berikut adalah beberapa fungsi utama dari algoritma Naive Bayes:
Klasifikasi Teks
Bisa digunakan untuk mengklasifikasikan informasi. Misalnya, email sebagai spam atau tidak spam. Atau, mengidentifikasi kategori artikel berita seperti olahraga, politik, atau hiburan.
Ini sangat efektif untuk masalah klasifikasi teks karena dapat menangani data dengan dimensi tinggi seperti kata-kata dalam dokumen.
Analisis Sentimen
Befungsi untuk menganalisis sentimen berdasarkan data. Contohnya adalah menganalisis ulasan produk untuk menentukan apakah sentimen pengguna bersifat positif, negatif, atau netral.
Ini dapat digunakan untuk memahami bagaimana perasaan pelanggan terhadap produk atau layanan. Sehingga, algoritma ini bisa membantu perusahaan untuk meningkatkan kualitas dan layanan mereka.
Deteksi Anomali
Memiliki fungsi untuk mendeteksi anomali. Contohnya adalah mengidentifikasi transaksi yang mencurigakan dalam sistem keuangan. Atau, mendeteksi aktivitas jaringan yang tidak biasa dan dapat menunjukkan adanya serangan siber.
Secara keseluruhan, algoritma Naive Bayes bisa meningkatkan keamanan dengan mendeteksi dan merespons ancaman dengan cepat.
Sistem Rekomendasi
Bisa dijadikan dasar untuk membuat sistem rekomendasi. Contohnya dalam sistem yang bisa merekomendasikan produk kepada pelanggan. Ini dilakukan berdasarkan riwayat pembelian mereka atau menyarankan film berdasarkan riwayat tontonan.
Fungsi ini bisa meningkatkan pengalaman pengguna dengan memberikan rekomendasi yang lebih relevan dan personal.
Cara Optimalkan Penggunaan Naive Bayes
Meskipun Naive Bayes adalah algoritma yang sederhana dan efisien, ada beberapa langkah untuk mengoptimalkan penggunaannya agar hasilnya lebih akurat dan relevan.
Berikut adalah beberapa cara untuk mengoptimalkan penggunaan Naive Bayes:
Pra-Pemrosesan Data
Pra-pemrosesan data adalah langkah awal yang sangat penting untuk mengoptimalkan model Naive Bayes. Langkah ini mencakup pembersihan data dari noise, duplikasi, dan nilai-nilai yang hilang dan dapat mengganggu kinerja model.
Selain itu, normalisasi data juga sangat berguna terutama untuk Gaussian Naive Bayes. Pasalnya, ini bisa mengurangi variabilitas dalam data dan membantu model bekerja lebih efisien.
Pemilihan Fitur
Pemilihan fitur adalah langkah penting lainnya. Menggunakan teknik seleksi fitur membantu dalam memilih fitur yang paling relevan. Sehingga, ini bisa mengurangi kompleksitas data dan risiko overfitting.
Dalam analisis teks, teknik ekstraksi fitur seperti TF-IDF atau Word Embeddings dapat mengubah teks menjadi fitur yang lebih informatif. Selain itu, ini juga bisa meningkatkan kinerja model secara keseluruhan.
Validasi dan Cross-Validation
Validasi model menggunakan teknik cross-validation adalah metode yang efektif untuk mengevaluasi kinerja model secara lebih akurat. Cross-validation membantu mencegah overfitting dengan memastikan model bekerja baik pada data yang belum pernah dilihatnya.
Selain akurasi, menggunakan metrik evaluasi lain seperti precision, recall, F1-score, dan AUC-ROC memberikan gambaran yang lebih komprehensif tentang kinerja model.
Pengolahan Data Teks
Dalam pengolahan data teks, pembersihan teks dengan menghapus stop words, stemming, dan lemmatization adalah langkah penting. Tujuannya adalah untuk mengurangi variasi kata yang tidak perlu.
Baca Juga: 4 Tahap Preprocessing Data, Beserta Penjelasan & Studi Kasus
Kelebihan dan Kekurangan Naive Bayes
Meski menawarkan beragam fungsi, Naive Bayes tetap punya kekurangannya juga. Berikut MinDi jabarkan beberapa kelebihan dan kekurangan Naive Bayes:
Kelebihan Naive Bayes
Berikut adalah beberapa kelebihan Naive Bayes yang menjadikannnya unggul:
Sederhana dan Mudah Dipahami: Parameternya mudah diestimasi, sehingga sering algoritma ini mudah dipelajari.
Skalabilitas yang Baik: Cepat dan efisien, serta punya kebutuhan penyimpanan yang rendah.
Mampu Menangani Data Berdimensi Tinggi: Efektif untuk klasifikasi dokumen dan data dengan banyak fitur.
Kekurangan Naive Bayes
Sementara itu, beberapa kekurangan Naive Bayes yang perlu kamu pertimbangkan adalah:
Masalah Zero Frequency: Probabilitas bisa menjadi nol jika suatu kategori tidak ada dalam data pelatihan. Sehingga, membutuhkan penggunakan smoothing Laplace untuk mengatasinya.
Asumsi Independensi yang Tidak Realistis: Asumsi bahwa fitur-fitur independen sering tidak terpenuhi di dunia nyata, sehingga akurasinya kurang.
Yuk, Belajar Ilmu Data & Machine Learning di Bootcamp Dibimbing.id
Apakah sekarang kamu sudah paham tentang manfaat dari algoritma Naive Bayes? Untuk membangun dan mengimplementasikannya, dibutuhkan pemahaman tentang klasifikasi data, pengolahan data teks, dan probabilitas.
Kalau tertarik, kamu bisa mempelajarinya dengan ikutan Bootcamp Data Science dari Dibimbing.id! Di sini, kamu bakal diajarin data science dari awal hingga bareng ahli-ahli data science di industri.
Kamu juga bakal mempraktikan teori yang diajarkan dalam real-case project. Selain itu, program ini juga dirancang dengan kurikulum yang beginner-friendly. Jadi, kalau baru mulai pun, kamu tetap bisa mengikuti pelajarannya dengan mudah.
Bukan cuma pembelajarannya yang beginner-friendly, program ini juga ada jaminan kerjanya! Ini sudah dibuktikan oleh 94% lulusan Dibimbing yang berhasil dapat pekerjaan seusai program selesai.
Menarik, bukan? Yuk, segera daftar dan kembangkan keahlianmu di data science bareng Dibimbing.id!
Referensi
Naive Bayes Classifiers [Buka]
What are Naïve Bayes Classifiers? [Buka]
Naïve Bayes Algorithm: Everything You Need to Know [Buka]
Naive Bayes Explained: Function, Advantages & Disadvantages, Applications [Buka]

Siti Khadijah Azzukhruf Firdausi
Khadijah adalah SEO Content Writer di Dibimbing dengan pengalaman menulis konten selama kurang lebih setahun. Sebagai lulusan Bahasa dan Sastra Inggris yang berminat tinggi di digital marketing, Khadijah aktif berbagi pandangan tentang industri ini. Berbagai topik yang dieksplorasinya mencakup digital marketing, project management, data science, web development, dan career preparation.
